 官方网站-首页官方网站-首页
官方网站-首页官方网站-首页
新闻中心

发布时间:2025-03-28 10:00:29
阅读量:456次
打造“千里眼”的非结构光场智能成像技术
对于很多摄影圈资深人士来说,Lytro这个名字既如雷贯耳,又显得分外陌生。这曾是一家生产新型光场成像设备的初创企业,从2006年成立伊始,Lytro凭借其惊艳的产品和多项专利,一时间成为资本市场炙手可热的宠儿。但如今,除了部分摄影爱好者手中的珍藏品,我们已经难觅Lytro的踪迹了。
由清华大学、凌云光技术股份有限公司等多家单位共同完成的科研项目“非结构光场智能成像关键技术与装备”荣获2021年度北京市科学技术奖技术发明一等奖。该项科研成果将光场成像技术的发展推向了一个全新的高度。那么光场成像是否会在新技术的加持下焕发新生呢?
光场:既要“看得清”,又要“看得全”
说起“光场成像”,就要从那个生僻的物理概念——“光场”说起。在物理学领域里,“场”是一个被广泛应用的概念,我们耳熟能详的有“电场”“磁场”“引力场”等。对于这一抽象的物理学术语,我们可以简单地理解为物理量在时间和空间中的分布状态。从物理学的视角看去,光可不只是诗人在黑暗中寻找的圣物,而是可以用严谨的数学模型表达的物理概念。
早在200多年前,电磁学之父法拉第就在他的一篇演讲中提出,光应该像磁场一样,被理解为一个“场”,这算是光场理论的起源。此后,麦克斯韦提出了将电、磁、光统归为电磁场现场的麦克斯韦方程组,为光场理论的发展打下了重要基础。1936年,物理学家亚历山大·格尔顺(AlexanderGershun)在他的论文中正式提出了“光场”这一概念,并首次对光场进行建模。不过一直到20世纪末,人类才在光场理论上取得了实质性突破,1991年麻省理工学院教授爱德华·阿德尔森(E.H.Adelson)
等学者,提出了全光函数,为光场理论建立了一套清晰的数学模型。阿德尔森用一个7维函数,将光线在空间中的分布简洁明了地表达出来。在阿德尔森的理论中,全光函数将物体所发出或反射的光解析成7个维度的信息:光的空间位置(用空间坐标系x,y,z表达),光线入射角度(用球坐标系的角度值θ,Φ表达),波长(用λ表达)和时间(用t表达)。全光函数的提出,将人类看得见却摸不着的光,完整地拆解开来呈现在人类面前。既然光线本身包含了这些维度的信息,那么如果我们在空间内遍布数量众多的观察光线的位置,那么由此记录下这个空间内光线的动态分布状态,就可以被理解为“光场”。
全光函数的提出推动了“光场理论”的发展与完善,也为科学家指明了研究方向——光场成像技术。我们知道,传统的数码相机是由光学镜头、影像传感器和影像处理器三大核心部件组成的,自然界三维场景发出、反射或散射的光线,被单镜(jìng)头(tóu)捕(bǔ)捉(zhuō)并(bìng)聚(jù)焦(jiāo),经(jīng)由(yóu)影(yǐng)像(xiàng)传(chuán)感(gǎn)器(qì)转(zhuǎn)换(huàn)为(wèi)数(shù)字(zì)信(xìn)号(hào),最(zuì)后(hòu)交(jiāo)给(gěi)影(yǐng)像(xiàng)处(chù)理(lǐ)器(qì)变(biàn)成(chéng)二(èr)维(wéi)图(tú)像(xiàng)。清(qīng)华(huá)大(dà)学(xué)方(fāng)璐(lù)教(jiào)授(shòu)介(jiè)绍(shào)道(dào):“毕(bì)竟(jìng)光(guāng)是(shì)一(yī)个(gè)高(gāo)维(wéi)的(de)信(xìn)号(hào),普(pǔ)通(tōng)成(chéng)像(xiàng)设(shè)备(bèi)无(wú)法(fǎ)将(jiāng)光(guāng)场(chǎng)内(nèi)这(zhè)些(xiē)高(gāo)维(wéi)信(xìn)号(hào)全部(bù)、高(gāo)速(sù)并(bìng)实(shí)时(shí)地(de)转(zhuǎn)换(huàn)成(chéng)一(yī)个(gè)电(diàn)子(zi)信(xìn)号(hào)。”传(chuán)统(tǒng)成(chéng)像(xiàng)设(shè)备(bèi)只(zhǐ)能(néng)记(jì)录(lù)光(guāng)场(chǎng)中(zhōng)的(de)光(guāng)亮(liàng)信(xìn)息(xi),对(duì)光(guāng)的(de)方(fāng)向(xiàng)等(děng)信(xìn)息(xi)束(shù)手(shǒu)无(wú)策(cè),导(dǎo)致(zhì)深(shēn)度(dù)信(xìn)息(xi)的(de)丢(diū)失(shī),且(qiě)能(néng)获(huò)取(qǔ)的(de)总(zǒng)信(xìn)息(xi)量(liàng)受(shòu)到(dào)影(yǐng)像(xiàng)处(chù)理(lǐ)器(qì)像(xiàng)素(sù)数(shù)量(liàng)的(de)限(xiàn)制(zhì)。因(yīn)此(cǐ),“‘看(kàn)得(de)清(qīng)’和‘看得全’这对矛盾一直困扰着人们。举个大家日常拍照上的例子,广角镜头可以把照片拍得很宽很大,分辨率却不甚精确。而长焦镜头可以拍得很远很清晰,却只能覆盖一片很小的区域。”方璐(lù)说(shuō)。
光(guāng)场(chǎng)成(chéng)像(xiàng)的(de)前(qián)世(shì)今(jīn)生(shēng)
近(jìn)年(nián)来(lái),光(guāng)场(chǎng)采集感(gǎn)知(zhī)重(zhòng)建(jiàn)理(lǐ)论(lùn)及(jí)技(jì)术(shù)的(de)进(jìn)步(bù)为(wèi)我(wǒ)们(men)指(zhǐ)出(chū)了(le)另外一条思路:如果我们将全光函数中所有的参数都捕捉到,成像效果不就能做到既看得全也看得清吗?答案是(shì)肯(kěn)定(dìng)的(de)。不(bù)过(guò),全光(guāng)函(hán)数(shù)包(bāo)含(hán)了(le)光(guāng)线(xiàn)多(duō)达(dá)7个(gè)维(wéi)度(dù)的(de)信(xìn)息(xi),显(xiǎn)然(rán)还(hái)是(shì)过(guò)于(yú)复(fù)杂(zá)了(le),而(ér)且(qiě)并(bìng)不(bù)是(shì)所(suǒ)有(yǒu)维(wéi)度(dù)的(de)信(xìn)息(xi)在(zài)拍(pāi)摄(shè)时(shí)都(dōu)用(yòng)得(de)着(zhe)。于(yú)是(shì)安(ān)德(dé)尔(ěr)森(sēn)的(de)后(hòu)继(jì)者(zhě)们(men)将(jiāng)该(gāi)函(hán)数(shù)做(zuò)了(le)简(jiǎn)化(huà),波(bō)长(zhǎng)λ被(bèi)简(jiǎn)化(huà)为(wèi)记(jì)录(lù)红(hóng)、绿(lǜ)、蓝(lán)三(sān)原(yuán)色(sè),时(shí)间(jiān)t被(bèi)简(jiǎn)化(huà)为(wèi)记(jì)录(lù)不(bù)同(tóng)帧(zhèng),这(zhè)样(yàng)函(hán)数(shù)就(jiù)被(bèi)简(jiǎn)化(huà)为(wèi)只(zhǐ)包(bāo)含(hán)位(wèi)置(zhì)(x,y,z)与(yǔ)光(guāng)线(xiàn)入(rù)射(shè)角(jiǎo)度(dù)(0,Φ)5个(gè)维(wéi)度(dù)信(xìn)息(xi)。此(cǐ)后(hòu)又(yòu)被(bèi)进(jìn)一(yī)步(bù)降(jiàng)到(dào)了(le)4维(wéi):即(jí)通(tōng)过(guò)记(jì)录(lù)一(yī)条(tiáo)光(guāng)线(xiàn)穿(chuān)过(guò)两(liǎng)个(gè)平(píng)行(xíng)平(píng)面(miàn)的(de)坐(zuò)标(biāo)(分(fēn)别(bié)用(yòng)u,v和(hé)x,y两(liǎng)个(gè)坐(zuò)标(biāo)系(xì)表(biǎo)示(shì)),就(jiù)能(néng)得(de)到(dào)光(guāng)线(xiàn)的(de)位(wèi)置(zhì)与(yǔ)方(fāng)向(xiàng)信(xìn)息(xi)。如(rú)果(guǒ)将(jiāng)这(zhè)个(gè)双(shuāng)平(píng)面(miàn)模(mó)型(xíng)套(tào)用(yòng)在(zài)普(pǔ)通(tōng)成(chéng)像(xiàng)系(xì)统(tǒng)的(de)结(jié)构(gòu)上(shàng),那(nà)么(me)其(qí)中(zhōng)u-v平(píng)面(miàn)就(jiù)是(shì)主镜(jìng)头(tóu)中(zhōng)心(xīn)所(suǒ)在(zài)平(píng)面(miàn),x-y平(píng)面(miàn)是(shì)影(yǐng)像(xiàng)传(chuán)感(gǎn)器(qì)所(suǒ)在(zài)平(píng)面(miàn),这(zhè)样(yàng)通(tōng)过(guò)采集光(guāng)线(xiàn)穿(chuān)过(guò)两(liǎng)个(gè)平面时所产生的4个维度信息,理论上就能兼顾到“看得全、看得清”的效果。问题在于,要借助什么样高科技的神器才完成这样的采集工作呢?“要兼顾既看得全又看得清,就意味着依靠单个镜头和单个影像传感器的系统根本无能为力。这时人们就想到:能否把多个相机放在一起形成阵列,通过‘量变引起质变’的思路来实现?”方璐介绍道。初代光场成像技术的解决方案是在影像传感器前,用数量众多的单镜头组成阵列,形成类似于昆虫复眼的结构,对u-v和x-y平面的信息进行采集,然后通过数字调焦的形式进行图像还原。这样就形成了“先拍照,后对焦”的特点,省去了传统成像设备同时对焦和拍照导致拍摄不清晰的麻烦。
2006年,美国斯坦福大学的马克·勒沃伊(MarcLevoy)团队根据这一思路研制出了阵列式光场成像系统,这个身形巨大的装置通过不同位置的相机同时曝光进行光场信息采集,从而迈出了光场成像技术落地的第一步。2012年,美国杜克大学的戴维·布雷迪(DavidBrady)团队在顶级学术期刊《自然》上发表了世界上首款亿像素级阵列式光场成像系统,像素分辨率达到当年数码相机的30多倍,能捕捉到几倍于人眼感知能力的细节。但体积和重量的限制导致这些阵列成像设备只能止步于实验室。此外,在这种技术里,“每个相机采用同(tóng)样(yàng)的(de)尺(chǐ)度(dù),并(bìng)且(qiě)位(wèi)置(zhì)和姿态固定,只有一种拍摄模式,依赖事先标定的参数进行重建,系统的鲁棒性和扩展性都受限。”方璐介绍道,“如果有(yǒu)相(xiāng)机(jī)在(zài)成像过程中受到扰动,整个阵列系统的工作都会受到影响,需要进行重新标定。”
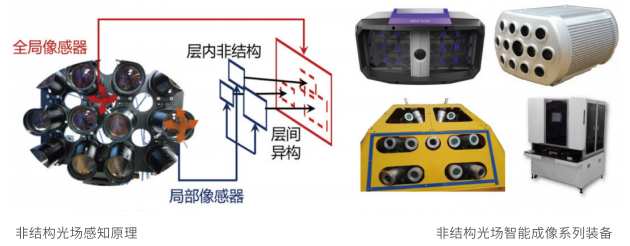
欲穷千里目,智能技术来相助
方璐带领团队另辟蹊径,提出了非结构光场阵列感知技术。不同于之前,非结构光场阵列感知技术的特(tè)征(zhēng)是(shì)“层(céng)内(nèi)非(fēi)结(jié)构”和“层间异构”:层内非结构突破了结构固化的制约,使得阵列系统具有场景自适应成像的能力;层间异构克服了尺度单一的瓶颈,使得阵列系统的感知尺度和维度可扩展。非结构光场阵列感知技术不再依赖复杂的硬件设计和烦琐的系统标定,而是借助人工智能,通过阵列结构自适应感知、跨尺度映射融合等技术,直接利用多尺度图像内容进行计算重建,同样的硬件资源条件下,大幅提升了系统的成像效率与鲁棒性。这一系列环环相扣的技术创新,大大降低了光场阵列系统的复杂程度,节约了硬件带来的高昂成本,让计算摄像和人工智能技术有了更多施展空间,突破了传统光学成像的瓶颈。
当然,这种全新的技术,是让几十个不一样的成像设备整合在一起工作,这背后算法部分的技术难度是可想而知的。“毕竟软件和算法的成本与迭代周期是远小于硬件系统的,我们把硬件制作的难度降低,让更多的工作留给算法去做,让智能成像成为可能,这种‘非结构光场感知’新范式使得光场成像真正实现了‘鲁棒性’。”方璐介绍道。
在人工智能技术的加持下,除了鲁棒性,非结构光场智能感知技术同时实现了另一大优势,即可扩展性:这种非结构光场阵列系统可以灵活地调整阵列的数量和组合方式,以适应不同的应用场景需求。对此,方璐指出:“要知道,鲁棒性和可扩展性这两大优势,对于技术的应用意义重大。在这两项优势加持下,这一新技术才有可能应用到未来多个不同领域中。”从工业检测到公共安全,再到智慧城市,光场成像在B端的应用前景十分广阔。方璐认为,目前的非结构光场成像技术,并不是给摄影爱好者去品鉴的,而是供智能无人系统进行识别分析之用的。那么在这种应用场景下,追求高分辨率就并不是唯一的目标。她进一步指出:“对此,我们也在研究‘感算一体’的成像技术,将计算移到前端,在成像的同时就计算出目标物体的特征和位置,这就省去了传统光场成像对图片压缩和解压,以及后续的目标特(tè)征提取与识别等烦琐步骤,这节约的资源与功耗是巨大的。”
非结构光场智能成像技术所面临的另外一个问题就是数据。因为现阶段人工智能算法开发迭代对于数据集的依赖是非常大的。方璐对此说道:“但目前国际上常用的视觉数据集大多是少场景、少对象、关系简单,可能就只有一只猫、一条狗、一辆车这样的信息。这就难以呈现复杂真实的场景,难以支撑面向大场景多对象复杂对象(xiàng)的新一代人工智能理论和算法的研究。”在这样的数据集里进行训练的人工智能算法,一旦放在类似“万人(rén)跑(pǎo)马(mǎ)拉(lā)松(sōng)”这(zhè)样(yàng)的(de)壮(zhuàng)观(guān)场(chǎng)景(jǐng)中(zhōng),可(kě)能(néng)就(jiù)力(lì)不(bù)从(cóng)心(xīn)了(le)。因(yīn)此(cǐ),方(fāng)璐(lù)带(dài)领(lǐng)团(tuán)队(duì)构(gòu)建(jiàn)了(le)PANDA数(shù)据(jù)平(píng)台(tái)(全称GigaPixel-levelHuman-centricVideoDataset),具(jù)有(yǒu)大(dà)场(chǎng)景(jǐng)(平(píng)方(fāng)千(qiān)米(mǐ)级(jí)别(bié)范(fàn)围(wéi))、高(gāo)分(fēn)辨(十亿像素级,支持百米对象识别)、多对象复杂关系(万级对象,尺度变化超百倍,遮挡关系复杂,交互行为丰富)的特点,填补了大场景下高密度群体对象数据平台的空白,为探索人工智能新(xīn)理(lǐ)论(lùn)和(hé)新(xīn)方(fāng)法(fǎ)提(tí)供(gōng)了(le)不(bù)可(kě)或(huò)缺(quē)的(de)数(shù)据(jù)基(jī)础(chǔ)。
立(lì)足(zú)于(yú)人(rén)工(gōng)智(zhì)能(néng)技(jì)术(shù),非(fēi)结(jié)构(gòu)光(guāng)场(chǎng)智(zhì)能(néng)成(chéng)像(xiàng)技(jì)术(shù)为(wèi)未(wèi)来(lái)的(de)光(guāng)场(chǎng)成(chéng)像(xiàng)技(jì)术(shù)指(zhǐ)明(míng)了(le)一(yī)条(tiáo)全新(xīn)的(de)赛道。谈到该技术的应用前景,方璐充满信心:“首先,我们会将技术从现在的宏观场景向微观场景普及,在未来会进一步向天文远观场景扩展,这背后的研发思路是一脉相承的。其次,人工智能算法还有待于进一步突破和推进:未来的成像目标是将性能做到极致,实现光速感知计算,这对于人工智能算法的要求是越来越高的。”



