 官方网站-首页官方网站-首页
官方网站-首页官方网站-首页
新闻中心

发布时间:2025-05-07 09:30:05
阅读量:416次
【导语】量子计算正蓬勃发展,但“它到底有什么用”的问题依然悬而未决。本文作者认为,当前正是大力推动量子算法的时刻,应降低原有要求,寻找可验证且实用的算法。理论物理学家John Preskill也推荐了本文,呼吁采取更务实的方法来探索量子计算的新应用。接下来,让我们一同深入探讨量子算法的现状与挑战,以及未来的发展方向(xiàng)。
当(dāng)前(qián),量(liàng)子(zi)计算领域蓬勃发展,却仍面临“它到底有什么用”的本质问题。在本文作者来看,在这样的环境下,正是大力推动量子算法的时刻,应降低对量子算法原有要求,寻找可验证且实用的算法,呼吁理论家积极探索,推动量子计算突破瓶颈。值得一提的是,本文得到了理论物理学家John Preskill的推荐:“如果你对量子计算感兴趣,我强烈推荐加州理工学院学生robbieking1000的这篇文章,呼吁采取‘更务实(scrappier)的方法’来寻找新的应用。”
撰文 | robbieking1000
翻译 | 一二三
量子计算正处在一个奇特的阶段。技术层面上,经过数十亿美元投资和数十年的研究,实用的量子计算机正逐步接近实现。但令人尴尬的是,如今人们对量子计算最常提出的问题,仍然和20年前一样:量子计算机到底能做什么?诚实的回答暴露了房间里的大象:我们至今也没有完全的答案。对于像我这样的理论家来说,这既是一种挑战,也是一种行动的召唤。
技术动能
假设几十年后我们仍未拥有实用的量子计算机,原因会是什么?不太可能是因为遇到了无法逾越的工程障碍。量子纠错的理论基础是坚实的,目前已有多个平台接近或低于纠错阈值(例如哈佛、耶鲁、谷歌)。实验家们相信,今天的技术有望将逻辑比特扩展到100个并实现10^6次门操作——进入所谓的“兆量子位时代”(megaquop era)(译者注:该说法由John Preskill提出,即量子处理器能够执行百万级或十亿级量子操作的时代。这里的'mega'并非精确指代一百万,而是表示百万量级的近似范围)。如果我们在接下来的几十年中投入1000亿美元,很可能会建成一台大型量子计算机。
但更令人担忧的可能是:量子计算缺乏足够的应用动力,无法为如此巨大的研发和基础设施投资提供正当性。这可以与核聚变作个比较,和量子计算一样,核聚变面临着巨大的科学和工程挑战。但如果核聚变实验室成功建成反应堆,其应用价值将是显而易见的。反观量子计算,它更像是一把寻找钉子的铁锤。
尽管如此,量子计算领域的产业投资目前正在加速增长。为了维持这种动能,必须在投资增长和硬件进步的同时,推进算法能力的发展。发现量子算法的时机,就是现在。
赋能理论家
理论研究具有前瞻性和预测性。比如Geoffrey Hinton的工作为今天的人工智能革命奠定了基础。而几十年后,随着硬件资源的丰富,AI已成为一门更偏向实证性的学科。我期待量子硬件也能早日步入繁荣,但现在还未到时候。
今天的量子计算,仍是理论家拥有巨大影响力的领域。Peter Shor几页数学推导,激励了数以千计的研究者、工程师和投资人投身此领域。也许读这篇文章的人中,有人能再写几页新的论文,由此奠定行业未来变革的基础。很少有地方像这里一样,数学能够发挥如此巨大的实际影响。整个实验家、工程师和企业界群体,都在期待理论家的新思路。
挑战
传统上,人们认为理想的量(liàng)子(zi)算(suàn)法(fǎ)应(yīng)具(jù)备(bèi)三(sān)大(dà)特(tè)性(xìng):
1. 可(kě)证(zhèng)明(míng)的(de)正(zhèng)确(què)性(xìng):确(què)保(bǎo)可(kě)靠(kào)执(zhí)行(xíng)量(liàng)子(zi)电(diàn)路即(jí)可(kě)得(de)到(dào)正(zhèng)确(què)结(jié)果(guǒ);
2. 经(jīng)典(diǎn)难(nán)解(jiě)性(xìng):量(liàng)子(zi)算(suàn)法(fǎ)的(de)输(shū)出(chū),经(jīng)典(diǎn)算法难以在合理时间内(nèi)复(fù)现(xiàn);
3. 实(shí)用(yòng)性(xìng):有(yǒu)潜(qián)力(lì)解(jiě)决(jué)现(xiàn)实(shí)世(shì)界(jiè)中(zhōng)的(de)有(yǒu)意(yì)义(yì)问(wèn)题(tí)。
Shor算(suàn)法(fǎ)几(jǐ)乎(hu)满(mǎn)足(zú)了(le)这(zhè)三(sān)条(tiáo)标(biāo)准(zhǔn)。但(dàn)在(zài)实(shí)际(jì)探(tàn)索(suǒ)中(zhōng),绝(jué)对(duì)坚(jiān)持(chí)三(sān)条(tiáo)标(biāo)准(zhǔn)反(fǎn)而(ér)可(kě)能(néng)适(shì)得(de)其(qí)反(fǎn)。
可(kě)证(zhèng)明(míng)的(de)正(zhèng)确(què)性(xìng)很(hěn)重(zhòng)要,因为目前我们尚不能在大规模硬件上直接验证量子算法。但对于“经典难解性”,我们应要求到什么程度呢?毕竟,要严格证明一个问题经典难解,需要解决P vs NP这样的重大开放问题,这是不现实的。我们可以采用“软证明”,比如将问题规约(reduction)到已有的经典复杂性假设。
我认为我们应该将“可证明经典难解”这一理想替换为更加务实的标准:只要量子算法在平均情况下,相比已知最优的经典算法,取得超二次加速(super-quadratic speedup)即可(kě)。[注(zhù)1]
过于强调传统的难解性定义,可能反而妨碍新算法的发现,因为真正新颖的量子算法,很可能会引入全新的经典复杂性假设,与既有的假设有根本性不同。而这种提出新假设并攻破它的反复过程,本身就是帮我们寻找量子优势的高效路径。
此外,直接把目标瞄准为用量子算法“解决现有的实际问题”也可能是徒劳的。能够实现量子优势的基础性计算任务非常特殊,数量也非常少,但它们必然最终会成为量子应用的基石。我们应该寻找更多这样的基础任务,再考虑它们与具体应用匹配。
当然,区分哪些量子算法未来可能具有实际计算意义是很重要的。在现实(shí)世(shì)界(jiè)中(zhōng),计(jì)算(suàn)必(bì)须(xū)是(shì)可(kě)验(yàn)证(zhèng)或(huò)者(zhě)至(zhì)少(shǎo)可(kě)重(zhòng)复(fù)的(de),否(fǒu)则(zé)它(tā)没(méi)有(yǒu)实(shí)际(jì)意(yì)义(yì)。例(lì)如(rú),一(yī)个(gè)用(yòng)来(lái)计(jì)算(suàn)物(wù)理(lǐ)中(zhōng)可(kě)观(guān)测(cè)量(liàng)的(de)量(liàng)子(zi)模(mó)拟(nǐ)算(suàn)法(fǎ),如(rú)果(guǒ)在(zài)两(liǎng)台(tái)量(liàng)子(zi)计(jì)算(suàn)机(jī)上(shàng)得(de)到(dào)相(xiāng)同(tóng)的(de)结(jié)果(guǒ),那(nà)么(me)我(wǒ)们(men)就(jiù)有(yǒu)信(xìn)心(xīn)这(zhè)个(gè)结(jié)果(guǒ)是(shì)正确且有物理意义的。一些问题,如因式分解,自然容易经典验证,但我们可以把标准定得更低:一个有效的量子算法的输出至少应该能够被另一个量子计算机重复。
最后,还有一个至关重要的隐性第四要求,但常被忽视:如果明天你手上有一台量子计算机,你能立刻跑你的算法吗?这意味着,你不仅要有量子算法,还需要定义好一组输入分布。经典难解性应该基于输入分布的平均情况,而不是最坏情况。
在本小节结束之际,我要特别提醒大家:很多以可观测量的期望值为输出的量子算法提案,最终都因失败而告终。这类算法不具有经典难解性的常见原因是,期望值在输入分布上高度集中(即大多数输入给出的结果都很接近),那么对于一个简单的经典算法,每次输入后只需输出常见值,就能复现量子算法的结果。因此,我们应寻找那些对输入变化敏感、具有期望值输出显著波动的量子算法。
我们可以把以上优先级总结为以下挑战:
挑战
请找到一个量子算法及其输入分布,满足以下特性:
可证明的正确性:量子算法本身是正确的;
经典难解性:在输入分布的平均情况下,量子算法比最优的经典算法实现超二次加速;
潜在的应用价值:输出结果是可验证的,或者至少是可重复的。
示例与非示例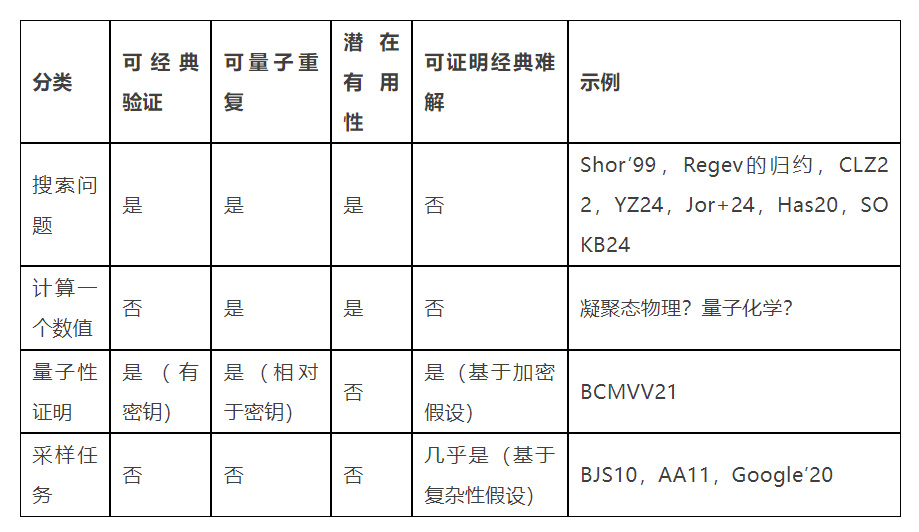
表1 我们可以根据输出类型将量子算法分类。搜索问题:它输出满足某种约束的比特串(如分解质因数、数据中隐藏特征、优化问题解等)。计算一个数值:输出某个物(wù)理(lǐ)量(liàng)的(de)近(jìn)似(shì)值(zhí)(如(rú)期(qī)望(wàng)值(zhí))。量(liàng)子(zi)性(xìng)证(zhèng)明:通过隐藏密钥设置的验证问题,确认设备的量子性。采样任务:从某个分布中抽样。
哈密顿量模拟(Hamiltonian simulation)或许是量子计算最广为人知的应用。物理学与化学中有许多自然界轻松计算但经典计算机无法企及的问题,量子计算可以直接模拟大自然,这让我们有充分的理由相信量子算法可以解决经典计算难解的问题。
已有一些例子显示,量子计算可以帮助解决未解的科学问题,比如Hubbard模型的相图或FeMoCo分子的基(jī)态能量。这(zhè)些(xiē)问(wèn)题(tí)无(wú)疑(yí)具(jù)有(yǒu)科(kē)学(xué)价(jià)值(zhí)。但(dàn)它(tā)们(men)是(shì)孤(gū)例(lì),我(wǒ)们(men)更(gèng)希(xī)望(wàng)有(yǒu)证(zhèng)据(jù)可(kě)以(yǐ)表(biǎo)明(míng)量(liàng)子(zi)计(jì)算(suàn)的(de)可(kě)解(jiě)问(wèn)题(tí)是(shì)无(wú)穷(qióng)无(wú)尽(jǐn)的(de)。我(wǒ)们(men)能(néng)否(fǒu)从强相关物理中获(huò)得(de)灵感,写(xiě)出(chū)一系列具体的哈密顿量模拟系统,其中存在经典难解的可观测量?这将为量子模拟持续且广泛的应用收集证据,也将帮助我们理解量子优势在哪里以及如何产生。
计算机科学界也做了大量关于“预言机分离”(oracle separation)的工作,如焊接树(welded trees)、傅换关联(forrelation),这增强了我们对量子计算机能力的信心。现在需要将这些oracle实例化为“明天就可以在真实设备上跑”的算法,这是初步测试算法所必需的。
除了哈密顿量模拟,还有其他几个重要的量子算法门类:包括求解线性方程组与微分方程的量子算法;用于机器学习的变分量子算法;用于优化问题的量子算法。
这些框架有时带有BQP完备性(即能模拟任何量子计算),但通常未指定输入分布。我们需要探索新的输入集合,寻找真正的超二次加速。BQP 完备性表明,人们已经将量子计算的概念转换成了不同的语言,这使得人们可以将现有的量子算法(如 Shor 算法)嵌入到自己的框架中。但为了发现新的量子算法,你必须找到一组不来自 Shor 算法的 BQP 计算的综合体系。
关于表1中提到的采样任务,其本身并没有实际意义,因为它们甚至不是量子可重复的。人们会想,采样任务能否以某种方式变得有用。毕竟,经典蒙特卡洛算法已经得到了广泛应用(译者注:该算法是一类基于随机采样的数值方法,广泛应用于强关联量子多体系统的模拟,例如凝聚态物理、核物理、冷原子物理等领域中的多体量子系统)。而采样的应用通常使用样本来提取有意义的信息或底层分布的特定特征,例如蒙特卡(kǎ)罗采样可以用于计算贝叶斯推断和统计物理中的积分。相比之下,从随机量子电路获得的样本缺乏任何可辨别的特征。但如果能从采样中提取出难以经典计算的有意义信号,这些任务也可以转变为数值计算类任务。
表1也指出量子性证明类应用没有实用性,这并不完全正确。一个有潜在应用的例子是可认证随机数生成,但这类应用通常属于密码学用途,而非计算用途。具体来说,量子性证明不能直接用来解决问题或者回答我们还不知道答案的问题。
最后,量子技术在传感、通信、带有量子记忆的学习、数据流处理等方面也有令人激动的应用前景。这些方向非常有趣,我希望在人类理解量子力学的第二个世纪能够创造出各种各样的能力。而眼下技术动力仍然集中在构建量子计算机以实现计算优势上,因此这方面的突破将产生最大的即时影响。
不必太害怕
在每年举办的QIP(量子信息处理)会议上,数百篇论文中,只有极少数研究尝试提出新的量子算法。鉴于其重要性,为什么这个数量还是如此之低?一个常见的解释是:量子算法研究太难了。不过,最近几年量子算法领域实际上已经取得了不少实质进展。从2000年到2020年,具有实用潜力的算法寥寥无几,而表格中列出的许多成果都是近5年内的突破。
在盲目乐观与消极悲观之间,采用一种“使命驱动”的探索心态,将能推动整个领域前进。我们应该允许自己采用更加探索性、务实的策略:在未被充分研究的问题上,或小数点后第三位的微妙信号中寻找量子优势。
实现意义重大的进步,其实门槛比看起来要低得多,即使是微小的前进,也是宝贵的。不要太害怕!
注释
[1] 由于量子误差校正的开销,单纯的二次加速(如Grover搜索)难以支撑实用量子优势,因此需要超二次加速。
本文基于知识共享许可协议(CC BY-NC)译自robbieking1000, Quantum Algorithms: A Call To Action.

特 别 提 示
1. 进入『返朴』微信公众号底部菜单“精品专栏“,可查阅不同主题系列科普文章。
2. 『返朴』提供按月检索文章功能。关注公众号,回复四位数组成的年份+月份,如“1903”,可获取2019年3月的文章索引,以此类推。
版权说明:欢迎个人转发,任何形式的媒体或机构未经授权,不得转载和摘编。转载授权请在「返朴」微信公众号内联系后台。



