 官方网站-首页官方网站-首页
官方网站-首页官方网站-首页
新闻中心

发布时间:2025-07-16 09:30:02
阅读量:348次
【导语】一项革命性的脑机接口技术横空出世,借助AI算法成功将大脑神经信号实时转化为自然语音,为神经疾病导致的失语患者带来了重新开口说话的希望。在Nature杂志上发表的这项研究中,加州大学戴维斯分校等机构的科研团队通过精密的系统设计和创新算法,实现了从大脑信号到个性化语音的突破。这一技术不仅标志着神经工程和脑机接口领域的重要进展,更为失语者重建语言、身份与人际连结提供了前所未有的可能。未来,随着技术的不断优化和推广,我们或将迈入一个全新的语言纪元,让思维本身成为交流的直接源泉。
一项新型脑机接口技术,借助 AI 算法将神经信号映射为预期声音,首次实现将脑活动实时转化为语音,为神经疾病失语者恢复对话能力提供可能。
撰文 | 常恺
“这就像我重新拥有了⾃⼰的声⾳。”
一位渐冻症患者在通过脑语⾳接⼝系统说出第一句话时如此表达。
2025年6⽉12⽇,由加州⼤学戴维斯分校(UC Davis)联合布朗⼤学、哈佛医学院附属⻢萨诸塞总医院及美国退伍军⼈事务部神经恢复中⼼组成的研究团队,在Nature杂志发表了一项引发全球关注的神经⼯程研究。他们⾸次实现了通过⼤脑信号直接⽣成⾃然语⾳的技术,让一位因渐冻症(ALS)失去发声能⼒的患者“重新开⼝”。
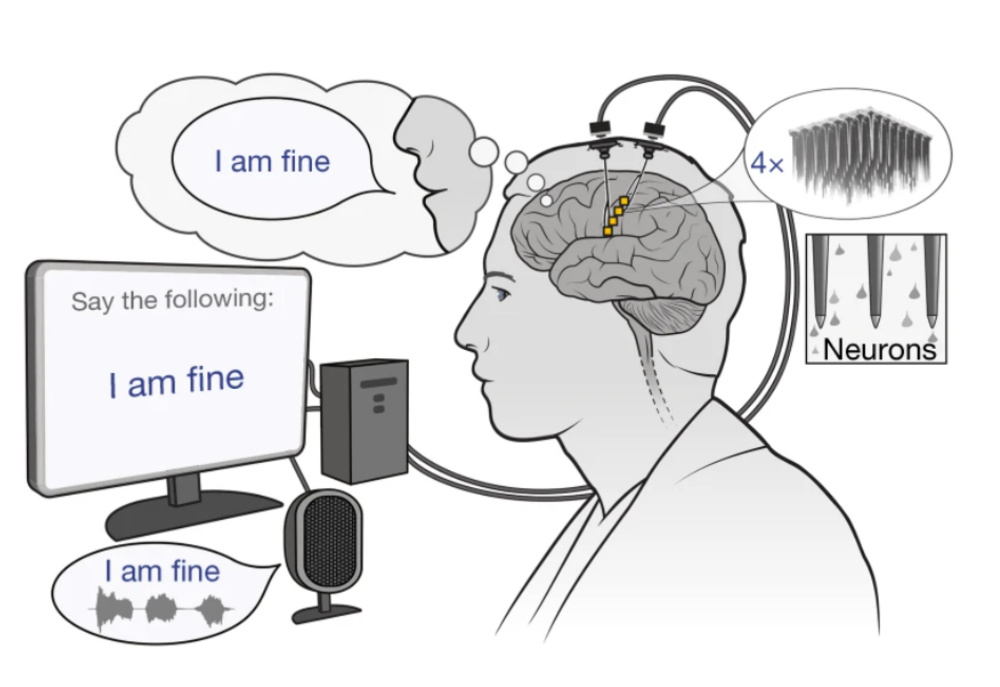
图1:脑—语音接口系统的工作原(yuán)理(lǐ)示(shì)意(yì)图(tú)。
⽤(⽤)⼤(⼤)脑(nǎo)说(shuō)话(huà):⾸(⾸)次(cì)实(shí)现(xiàn)⾃(⾃)然(rán)语(yǔ)⾳(⾳)的(de)脑(nǎo)机(jī)接(jiē)⼝(⼝)
在(zài)神(shén)经(jīng)⼯(⼯)程(chéng)和(hé)脑(nǎo)机(jī)接(jiē)⼝(⼝)领(lǐng)域,实(shí)现(xiàn)“⽤(⽤)⼤(⼤)脑(nǎo)直(zhí)接(jiē)说(shuō)话(huà)”一(yī)直(zhí)是(shì)一(yī)个(gè)意(yì)义(yì)⾮(⾮)凡却充满挑战的⽬标。过去的脑机接⼝⼤多依赖⽂字拼写或按钮输⼊,即便能合成语⾳,往往也机械⽽单调,缺乏⾃然语⾔的韵律和情感。⽽对于那些⽆法发声的⼈来说,语⾔从未在⼤脑中沉默,只是被困在了⽆声的意图之中。如今,科学家们终于找到了一种⽅式,让这些“沉默的语⾔”被真实听⻅。
此次发表在Nature上的研究,⾸次通过⼤脑运动⽪层的神经信号,实时⽣成带有语调、节奏与个性化⾳⾊的⾃然语⾳。这不仅让语⾔障碍患者能够重新“说话”,更让他们能⽤属于⾃⼰的声⾳、⾃⼰的⽅式进⾏交流。
对于参与试验的ALS患者来说,这是一次技术测试,更是一次语⾔⾝份的重建。他成功说出“你好”“今天感觉很好”等简单句⼦,并能灵活调控语调语⽓,甚⾄尝试哼唱旋律。这些表达,不再只是功能性的输出,⽽是具有⾃我⾊彩(cǎi)、情(qíng)感(gǎn)温(wēn)度(dù)和交流能⼒的完整语⾔。
从沉默到发声:⼤脑如何直接驱动真实语⾳
要实现如此⾃然流畅的语⾳表达,背后依赖的是一个⾼度精密的脑—语⾳接⼝系统。研究团队将整个流程设计为四个关键步骤:神经信号采集(neural recording)、神经解码(neural decoding)、语⾳合成(speech synthesis)和实时播放(real-time audio feedback),构建出一个完整的闭环路径,让意图真正转化为可听⻅、可互动的语⾔。
⾸先,研究⼈员在患者⼤脑左侧前中央回腹部(ventral premotor cortex)——这一控制⾯部和喉部(bù)运(yùn)动(dòng)的(de)关键区(qū)域——植(zhí)⼊(⼊)了(le)两(liǎng)组(zǔ)共(gòng)计(jì)256通(tōng)道(dào)微(wēi)电(diàn)极(jí)阵(zhèn)列(liè)(microelectrode arrays)。即(jí)便(biàn)患(huàn)者(zhě)已(yǐ)⽆(⽆)法(fǎ)发(fā)声(shēng),但(dàn)在(zài)“试(shì)图(tú)说(shuō)话(huà)”时(shí),⼤(⼤)脑(nǎo)依(yī)然(rán)会(huì)产(chǎn)⽣(⽣)可(kě)被(bèi)记(jì)录(lù)的(de)电(diàn)信(xìn)号(hào)。随(suí)后(hòu),这(zhè)些(xiē)神(shén)经(jīng)信(xìn)号(hào)被(bèi)输(shū)⼊(⼊)⾄(⾄)两(liǎng)套(tào)并(bìng)⾏(⾏)的(de)深(shēn)度(dù)神(shén)经(jīng)⽹(⽹)络(luò)模(mó)型(xíng)中(zhōng)进(jìn)⾏(⾏)解(jiě)码(mǎ):
•第(dì)一(yī)套(tào)模(mó)型(xíng)⽤(⽤)于(yú)预(yù)测(cè)语(yǔ)⾳(⾳)内(nèi)容(róng)(phoneme probabilities及acoustic features),即识别“说了什么”;
•第⼆套模型则专⻔提取语调和情绪等副语⾔信息(paralinguistic features),如语句是否为疑问句、是否强调某一词等。
这种“双路径解码”机制,不仅能还原语义信息,还能呈现语言中的情感和个性表达,使系统输出更接近真实人类语言。
由于患者无法清晰发声,研究团队面临缺乏“真实语音”训练数据的难题。为此,他们开发了一种创新算法:借助屏幕提示语引导患者进行“尝试说话”,并实时记录其神经活动。系统随后从这些神经信号中识别出音节边界,再通过语音合成技术(text-to-speech)生成对应的目标语音。最后,研究人员将合成语音与神经信号在时间上对齐,从而构建出神经—语音配对数据,间接还原出患者的“预期发音”,为神经解码模型的训练提供了可靠基础。
在此基础上,团队训练了一套基于 Transformer 架构的深度学习模型,每10毫秒预测一次语音的频谱与音高特征。该模型实现了“因果解码”能力,还对不同实验时段之间神经信号的波动进行了结构优化,以确保不同使用时间下的稳定性和精确性。
最终的语音输出由一套个性化声码器(personalized neural vocoder)完成。该系统通过模拟人类声带与发音机制,将神经解码得到的语言参数转化为清晰自然的语音,并通过扬声器实时播放给患者。这种闭环式音频反馈有助于重建大脑与语言表达之间的神经通路,也增强了交流的沉浸感。
为了最大限度保留个体特征,声码器在训练时还融⼊了患者早期的语⾳录⾳,使得合成的语音在音色、语调上更贴近患者原有的嗓⾳特征,具有⾼度个体化识别度。
整体而言,该系统在音素识别、语调判断等方面均表现出色。实验显示,该系统对疑问语调的识别准确率约为 90.5%,词语重读的识别准确率约为 95.7%;在部分自由表达任务中,合成语音的音频质量与提示语条件下生成结果相当(Pearson 相关系数约为 0.79±0.05)。整个过程在毫秒级时间窗⼝内完成闭环,从神经信(xìn)号(hào)产(chǎn)⽣到声⾳输出延迟极低,⼏乎可实现实时对话。这一速度远超以往的脑—机语⾳系统,真正做到了“⽤⼤脑实时说话”。
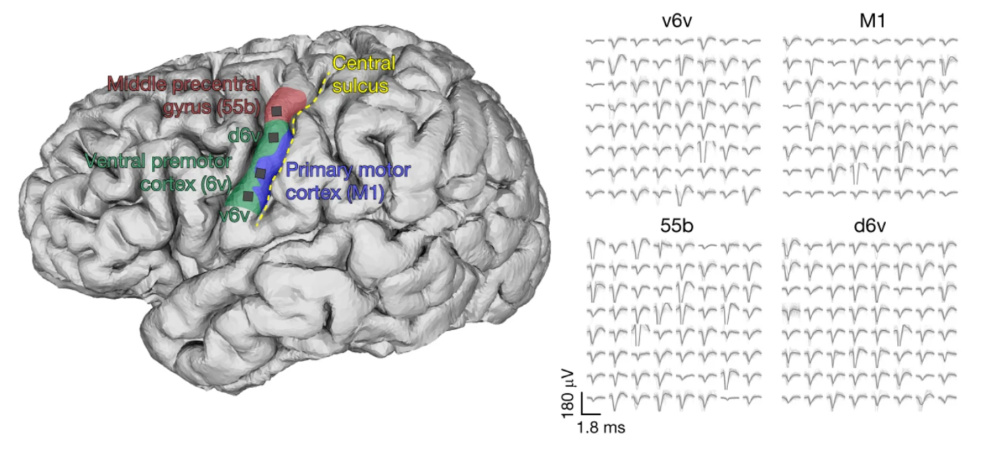
图(tú)2:语(yǔ)言(yán)相(xiāng)关脑(nǎo)区(qū)的(de)神(shén)经(jīng)信(xìn)号(hào)采集与(yǔ)放(fàng)电(diàn)波(bō)形(xíng)图(tú)。左侧图显示了研究中电极阵列的植入区域,包括中前中央回(Middleprecentral gyrus,55b)、腹侧前运动皮层(ventral premotorcortex,6v)、初级运动皮层(primary motorcortex,M1)以及相关子区(d6v、v6v)。黄色虚线标示中央沟(central sulcus)作为解剖参照。右侧图为从每个脑区采集到的神(shén)经放电波形(spike waveforms),展示了不同皮层区域中神经元的典型放电模式。这些信号构成了接口系统语音解码的神经基础。
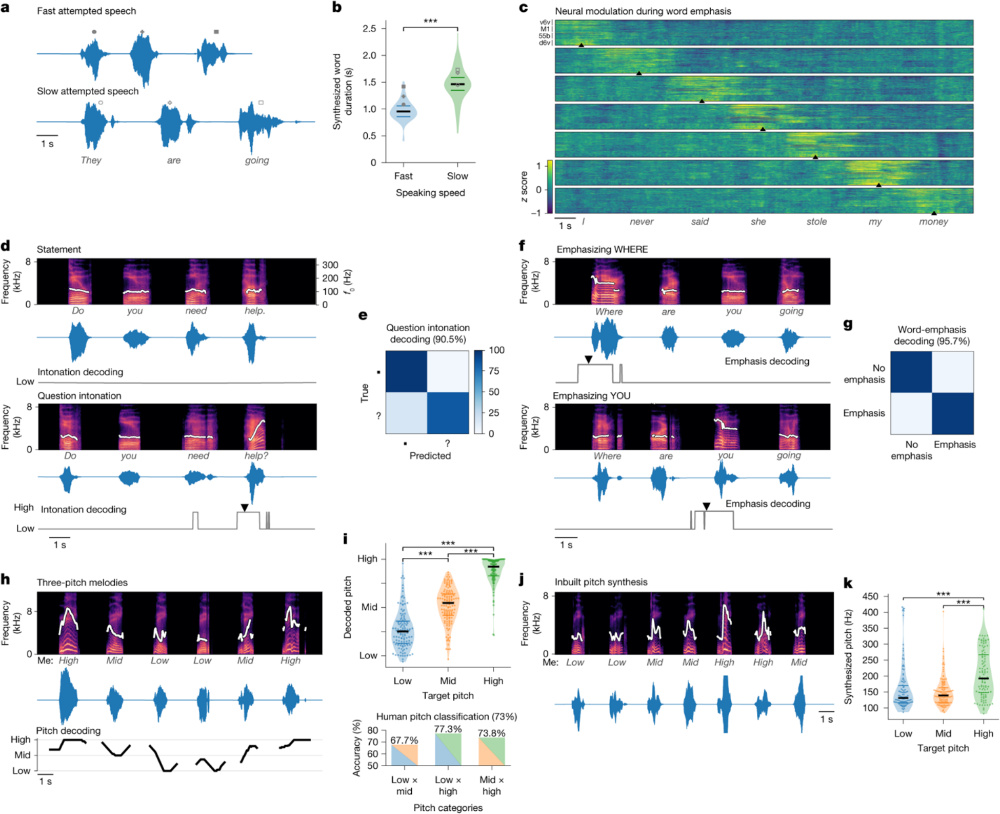
图3:脑—语⾳接⼝系统的表达⼒与语调控制能⼒。本图展示系统在语速调控(a–b)、词语重读(c)、语调识别(d–e)、强调重建(f–g)和⾳⾼合成(h–k)⽅⾯的多维解码能⼒。a–b:系统可区分快速与缓慢语速的神经意图,并合成相应节奏语⾳;c:在不同⽪层(M1、v6v、d6v、55b)中检测到与词语强调相关的神经调制;d–e:区分疑问句与陈述句语调,并实现⾼准确率的语调解码(90.5%);f–g:成功识别并再现句中不同词语的强调位置(如“Where” vs “You”);h–k:合成不同⾳⾼(Low,Mid,High)的旋律语⾳,并达到了与⽬标语调一致的频率分布(合成精度>73%)。
语⾔的未来:不仅是技术,更是权利的归还
这项研究的意义,不仅在技术层面实现了用“大脑说话”的突破,更在于它为失语者在重建语言、身份与人际连结提供了全新可能。在传统沟通手段失效的情况下,这一脑语音接口技术让沉默的大脑重新被听见,让表达不再依赖声音或动作,而直通思维本身。
为加速这一方向的发展,研究团队已将完整的数据与代码在GitHub(
Neuroprosthetics-Lab/brain-to-voice-2025)开源,并邀请全球研究者共同优化算法、拓展功能。未来,它有望推广至中⻛、脑瘫、喉癌术后等多类失语人群;与此同时,研究人员也在探索其与⾮侵⼊式脑电技术(如EEG)的结合,以进一步降低使用⻔槛;它还可能与AI语义理解系统融合,构建新—代⾃然语⾔交互平台。
尽管该研究已实现了神经信号到自然语音的实时转化,但目前仍处于早期探索阶段。在实验中,患者需要根据屏幕提示语进行“默念”或“尝试说话”,系统才能识别相应意图并合成语音。换句话说,当前的表达仍依赖于“外部引导”,尚未达到完全由大脑自主驱动的自由交流。
不过,研究团队也尝试在更开放的场景中进行测试。例如,在部分无提示的问答任务中(zhōng),系(xì)统依然能够生成清晰、自然的语音输出。这一结果提示:脑语音接口正朝着“无提示、自主表达(dá)”的(de)方(fāng)向迈进,为未来实现意图直接驱动语言奠定了技术基础。
当然,这项技术目前仅在一位ALS患者中完成验证,样本数量有限,仍不足以评估其在不同个体、不同病理状态下的通用性与稳定性。同时,从公开演示视频来看,系统生成的语音虽然具备个性化音色,但在语调灵活性、节奏自然度与情感表现方面,仍与真实人类对话存在一定差距。
要实现真正的日常实用化,该技术仍面临诸多挑战:如何从“提示语驱动”迈向“自由表达”?如何减少设备的侵入性、提升长期使用的稳定性与适配性?这些问题将决定脑语音接口能否从实验室走进真实生活的深度与广度。
但毋庸置疑,我们正在迈入一个新的语言纪元。未来的语⾔,不再依赖声带、⽂字或⼿势,⽽将直接来源于我们的思维本⾝。语⾔,原本就是我们存在的延伸。⽽今天的这项研究,让我们看到:即使在沉默之中,⼤脑依然有话可说。科技,正在帮助那些失去语⾔的⼈再次被世界听⻅。
注:本文封面图片来自版权图库,转载使用可能引发版权纠纷。

特 别 提 示
1. 进入『返朴』微信公众号底部菜单“精品专栏“,可查阅不同主题系列科普文章。
2. 『返朴』提供按月检索文章功能。关注公众号,回复四位数组成的年份+月份,如“1903”,可获取2019年3月的文章索引,以此类推。
版权说明:欢迎个人转发,任何形式的媒体或机构未经授权,不得转载和摘编。转载授权请在「返朴」微信公众号内联系后台。



